4 Hash functions
In this section, we take a detour from encryption to look at other cryptographic primitives. You might have encountered hash functions before, in a different field. However, we will see that hash functions in cryptography require some special properties. We will:
Briefly discuss some issues in cryptocurrencies, and how they can be solved with hash functions.
Define hash functions and their main properties.
Learn about the birthday paradox attack on hash functions.
Learn how to extend the domain of a hash function through the Merkle-Damgärd transformation.
4.1 Some issues in cryptocurrencies
Traditional currency is centralized, which means that there is an authority that dictates money policy, establishes ownership, and manages the whole system. On the other hand, in recent decades there has been a substantial effort in using cryptographic tools to build what we know as cryptocurrencies, which aim to be completely decentralized.
In this section, we discuss some issues that arise in decentralized systems. This is a very high level overview, based on the Bitcoin14 approach, and omits many technicalities for the sake of the exposition. Nevertheless, it will be enough to motivate the use of hash functions.
A coin, the monetary unit of a cryptocurrency, is nothing more than a unique bitstring \(ID\) that identifies is, and is accordingly called its identifier. An immediate problem arises regarding transferring ownership of a coin.
Problem 1 (Double-spending). Suppose that \(A\) buys something from \(B\) on the internet and pays with a coin \(ID\). What prevents \(A\) from using the same coin \(ID\) to buy something else from a different party \(C\)?
On very general terms, the solution is to publish every transaction that happens, so that the journey of each coin can be traced and thus its ownership can be established. In the problem above this means that, when \(A\) buys from \(B\), the message “\(A\) transfers the coin \(ID\) to \(B\)” is added to the public ledger. Then, after the ledger awards \(B\) ownership of the coin, they can send whatever \(A\) bought. Moreover, if \(A\) tries to spend the same coin again, \(C\) will notice in the ledger that the coin no longer belongs to \(A\), and the transaction will be denied. So, ignoring the logistics of checking and storing and increasingly large ledger, we would have solved the issue. But we still have to deal with the following problem.
Problem 2. Who keeps track of this public ledger? Who adds the new transactions? If there is no central authority, how do users agree on which transactions happened?
More concretely, imagine that there is a ledger of transactions \[t_1,t_2,\dots,t_n,\] and two different options \(t_{n+1},t_{n+1}'\) are claimed to be the next transaction by different parties:
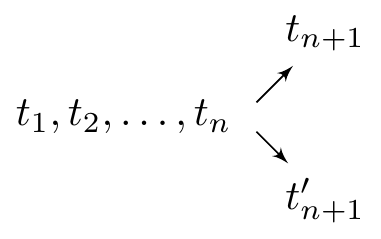
This situation is called a fork. The system is designed in such a way that users are encouraged to keep a consensus on a ledger of valid transactions. The general idea is that you have more of a say if you have more computational power, or more precisely if you have spent more CPU cycles in adding transactions to the ledger. So we need a way to “prove” that you have spent these cycles.
Let \[H:\{0,1\}^k\rightarrow\{0,1\}^\ell,\] for some \(k,\ell\in\mathbb{N}\), where in general \(k\) is much larger than \(\ell\), be an efficiently computable function. Suppose that we are interested in the problem of finding \(\mathbf x\) such that \(H(\mathbf x)=\mathbf 0\), where \(\mathbf 0\) is the string of zeros of length \(\ell\). If we know nothing about \(H\), the best we can do is try random inputs until we find a good one. On average, it would require \(2^\ell\) attempts to find such \(\mathbf x\). That is, whoever shows a solution \(\mathbf x\) has “proven” that he spent \(O(2^\ell)\) evaluations of \(H\) in solving the problem. This concept is known as a proof of work.
But back to transactions and the ledger: assume that the transaction \(t_{n+1}\), involving coin \(ID\), is to be added to the ledger. Then, our proof of work consists of producing \(\mathbf x\) such that the first \(T\) bits of \(H(ID|\mathbf x)\) are \(0\), for some \(T\). Once you have the solution, you can add the transaction, including \(ID\) and \(\mathbf x\), to the ledger. Note that solving the problem takes time \(O(2^T)\), whereas checking a solution is efficient, as it amounts to evaluating the function \(H\) just once with the transaction as input.
But isn’t this a lot of trouble to get someone’s transaction up in the ledger? The solution here is extremely simple: motivate the users of the network by awarding them newly mint coins when they successfully add a new transaction to the ledger. These users are the so-called miners, and the act of mining a cryptocurrency is just finding the right preimages of the function \(H\).
Thus, each addition to the ledger has two outcomes: transferring ownership of existing money and minting new money. And here’s the catch: as a miner, your new money is just valid a hundred transactions after your contribution to the ledger. Give a fork, honest users are encouraged to look at the longest ledger and ignore the rest. This encourages miners to work on the single longest ledger too, because the alternatives will be rejected by the users and thus the transactions in them virtually never happened. Therefore, miners might spend CPU cycles for nothing if they decide to work on shorter ledgers of a fork.
Another issue is that we want each new transaction to be “bound” to the previous ones. If the new transaction did not depend on the previous, nothing would prevent a malicious user from double-spending. This is also achieved through the function \(H\). Given previous transactions \(t_1,\dots,t_n\), the new transaction \(t_{n+1}\) will include its own transaction identifier \(H(t_1,\dots,t_n)\) besides \(ID\) and \(\mathbf x\). However, the ledger gets larger and larger, and we want the identifier to be small to keep things efficient. So \(H\) is mapping a very large set into a smaller one. The upshot is that there is no way for transaction identifiers to be unique.
Problem 3. What if there are two sets of transactions \(t_1,\dots,t_n\) and \(t_1',\dots,t_n'\) with the same identifier \(H(t_1,\dots,t_n)=H(t_1',\dots,t_n')\)?
Fortunately, although it is clear that there is no possible function \(H\) such that the outputs are unique, it will be enough if it is hard to find a pair of inputs with the same output, so that this issue with the identifiers cannot be exploited in practice.
4.2 Hash functions
The central piece of this whole apparatus seems to be the function \(H\), which we have not looked into yet. Clearly we will require some unconventional properties from this function. Let us summarize what we discussed about it:
The input is larger than the output, possibly by much.
Given \(\mathbf y\), it should be hard to find \(\mathbf x\) such that \(H(\mathbf x)=\mathbf y\).
It is hard to find \(\mathbf x,\mathbf x'\) such that \(\mathbf x\neq \mathbf x'\) and \(H(\mathbf x)=H(\mathbf x')\).
With this intuition in mind, let us introduce the solution to all of our problems: hash functions. At their core, hash functions are nothing more than functions that take an arbitrarily-long bitstring and output a bitstring of fixed length.
Definition 4.1 A hash function is an efficiently computable15 function \[H:\{0,1\}^*\rightarrow\{0,1\}^\ell,\] for some \(\ell\in\mathbb{N}\), and where \(\{0,1\}^*\) denotes the set of all bitstrings of any length. The process of computing a hash function is often called hashing, and the output is referred to as the hash.
Note that, unlike encryption, hash functions do not use any secret key. From a functionality point of view, this is all we need: a function that compresses bitstrings and is efficient enough to compute. However, to ensure the security of the cryptocurrency model described above, we will need an extra property.
We observe that hash functions must be public and deterministic, because different parties need to be able to arrive to the same result to verify a transaction.
The hash function is taking arbitrarily-large messages and producing fixed-length ones. That it, it is mapping a larger set into a smaller set. Therefore, there must be different strings that produce the same hash. Given a bitstring \(\mathbf b\), there might exist \(\mathbf b'\neq\mathbf b\) such that \[H(\mathbf b)=H(\mathbf b').\]
Nevertheless, we want this pair of bitstrings to be hard to find. This, and the observations at the beginning of Section 4.2, motivate the following set of definitions.
Definition 4.2 Let \(H\) be a hash function. We say that \(H\) is:
collision-resistant if it is hard to find two bitstrings \(\mathbf b, \mathbf b'\) such that \(\mathbf b\neq \mathbf b'\) and \(H(\mathbf b)= H(\mathbf b')\). In this case, the pair \((\mathbf b, \mathbf b')\) is called a collision of \(H\).
second preimage-resistant if, given \(\mathbf b\), it is hard to find \(\mathbf b'\neq \mathbf b\) such that they form a collision.
preimage-resistant if, given \(h\) sampled uniformly at random, it is hard to find a bitstring \(\mathbf b\) such that \(H(\mathbf b)=h\).
These properties are related by the following result.
Proposition 4.1 Let \(H\) be a hash function \[H:\{0,1\}^*\rightarrow\{0,1\}^\ell.\] If \(H\) is collision-resistant, then it is second preimage-resistant.
Exercise 4.1 Try to prove the proposition above by proving the contrapositive: assume that you can break second preimage resistance, and show how to use that to break collision resistance.
Informally, second-preimage resistance implies preimage resistance for any hash function that performs some “meaningful” compression of the input. This means that, for any hash function used in practice, if it is second-preimage resistant then it its preimage resistant, although the statement cannot be formally proven, due to some pathological counterexamples.
4.3 Birthday attacks
Assume that we are an adversary trying to attack a hash function \[H:\{0,1\}^*\rightarrow \{0,1\}^\ell,\] that is, we are trying to find a collision. The straightforward approach is the following: we choose random strings and compute their hashes, until two strings return the same hash. In the worst case, this requires \(2^\ell+1\) tries, since there are at most \(2^\ell\) different outputs. Therefore, it looks like the brute-force attack takes time \(O(2^\ell)\) to succeed. This would suggest that a hash function with output length \(\ell\) gives us a security level of \(\ell\).
In this section, we look into a generic attack that works for any hash function, which is based on the well-known birthday paradox from probability theory, and greatly improves over the above estimation. Consider the following problem.
Problem 4. There is a room with \(40\) independent students. How likely is that any two of them share the same birthday?
On first sight, one might think that this probability is quite low. After all, there are \(356\) days in the year, and only \(40\) students. Let us compute the actual probability, by solving a related problem: what is the probability of none of the \(40\) students sharing their birthday?
We start by numbering the students from \(1\) to \(40\), according to any criterion. To be able to reason more formally about the problem, we introduce the function \[\mathsf{bd}:\{1,\dots,40\}\rightarrow\{1,\dots,365\},\] which associates to each student its birthday. Then, the probability of student \(\#2\) not sharing a birthday with student \(\#1\) is \[\Pr[\mathsf{bd}(1),\mathsf{bd}(2)\text{ are different}]=\frac{364}{365},\] since there are \(364\) days of the year that are not the birthday of student \(\#1\). Let’s introduce student \(\#3\) into the picture, and let us consider the events:
\(\mathsf{A}\): \(\mathsf{bd}(3)\) is different from \(\mathsf{bd}(1)\) and \(\mathsf{bd}(2)\).
\(\mathsf{B}: \mathsf{bd}(1),\mathsf{bd}(2)\) are different.
Clearly, the intersection event is
- \(\mathsf{A}\cap\mathsf{B}: \mathsf{bd}(1),\mathsf{bd}(2),\mathsf{bd}(3)\) are pairwise different.
Then, using conditional probabilities, we have that \[\Pr[\mathsf{A}\cap\mathsf{B}]=\Pr[\mathsf{B}]\cdot\Pr[\mathsf{A}|\mathsf{B}]\] We already know \(\Pr[\mathsf{B}]\), so we are just missing the second term. If the birthdays of students \(\#1\) and \(\#2\) are different, then the probability of \(\#3\) having a different birthday from them is \[\Pr[\mathsf{A}|\mathsf{B}]=\frac{363}{365},\] since there are \(363\) days that are neither the birthday of \(\#1\) or \(\#2\). Thus, the probability of the three students having different birthdays is \[\Pr[\mathsf{A}\cap\mathsf{B}]=\frac{364}{365}\cdot\frac{363}{365}.\] By iterating this process for each student, we arrive at the conclusion that the probabilities of all \(40\) students having different birthdays is \[\frac{364}{365}\cdot\frac{363}{365}\cdot \dots \cdot\frac{326}{365} \approx 0.108768.\] In conclusion, the probability of two students sharing a birthday is approximately \[1-0.108768= 0.891232.\] This is actually a pretty high probability. This discrepancy between what one might naively expect and what actually happens is known as the birthday paradox. Below, you can find the solutions to Problem 4 for different numbers of students (rounded to six decimal positions).
| Students | Probability |
|---|---|
| \(10\) | \(0.116948\) |
| \(20\) | \(0.411438\) |
| \(40\) | \(0.891232\) |
| \(80\) | \(0.999914\) |
| \(128\) | \(0.999999\) |
So what does any of this have to do with breaking a hash function? What we have just done is computing the probability of finding two students such that the birthday function returns the same value on them. That is, we have found a collision of the birthday function! In doing so, we have assumed that the output of the birthday function behaves as the uniform distribution on \(\{1,\dots,365\}\). But, isn’t that exactly the effect that we want from a good hash function? That outputs look random and unrelated? So the moral of the story is that finding collisions in a hash function is actually much more likely that expected. More precisely, it can be proven with some careful probabilities analysis that, for any hash function \(H\) which outputs bitstrings of length \(\ell\), there is a decent probability of finding a collision after \(\sqrt{2^\ell}\) evaluations.
Compare this with our initial estimation. At the beginning of the section, we bounded a brute force attack by \(O(2^\ell)\). However, we now see that an attacker has a good probability of finding a collision in time \(O(2^{\frac{\ell}2})\). Thus, we conclude that a hash function with output length \(\ell\) gives us \(\ell/2\) bits of security. Or the other way around, if we want \(\ell\) bits of security, we need our hash function to have output length \(2\ell\).
4.4 The Merkle-Damgård transformation
As was the case for encryption, we often build hash functions in two steps. First, we build a hash function for fixed-length inputs, e.g. \[H:\{0,1\}^{2\ell}\rightarrow\{0,1\}^\ell,\] and then we extend them to arbitrarily-large input. We will not get into the details of concrete constructions, but will simply mention the SHA family of hash functions, which is the standard used in practice most of the time.16
A common way to realize this second step is to use the Merkle-Damgård transformation,17 which describes how to build from \(H\) another hash function \(\mathbf{H}\) that takes as input any string of length at most \(2^\ell-1\), and outputs a hash of length \(\ell\). It is clear that repeated applications of the transformation can make the input go as large as we want.
Similar to modes of operations in block ciphers, the Merkle-Damgård transformation starts by splitting the string \(\mathbf x\) of length \(L\leq 2^\ell\) to be hashed into blocks \[\mathbf x_1, \dots, \mathbf x_n,\] each of them of length \(\ell\).18 An additional block \(\mathbf x_{n+1}\) is added, containing a binary encoding of \(L\). Note that, because \(L\leq 2^n-1\), we can fit the encoding of \(L\) in \(n\) bits. Then, we recursively compute \[\mathbf z_i=H(\mathbf z_{i-1}|\mathbf x_i),\] for \(i=1,\dots,n+1\), and where \((\mathbf z_{i-1}|\mathbf x_i)\) means the concatenation of the bitstrings \(\mathbf z_{i-1}\) and \(\mathbf x_i\). Then, the hash of \(\mathbf x\) is \[\mathbf{H}(\mathbf x)=\mathbf z_{n+1}.\] As in modes of operation, there is no “previous block” in the first iteration, and so again we introduce an initialization vector \(\mathbf z_0\), which can be set to the string of \(0\)’s of length \(n\), or any other bitstring. There is no need for the IV to be secret.
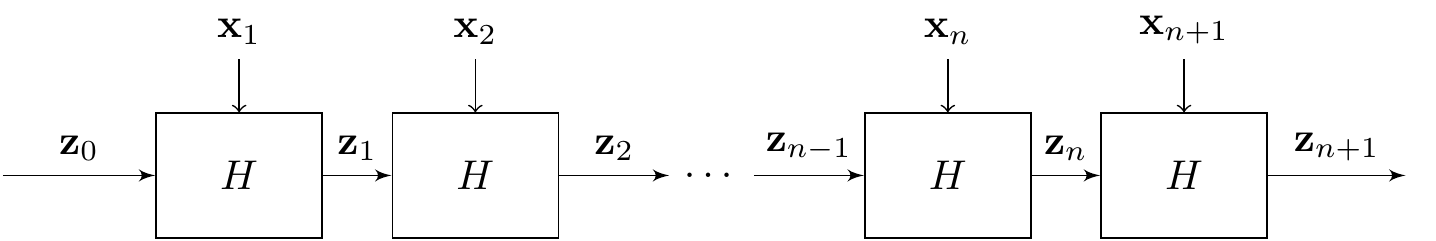
Proposition 4.2 If \(H\) is a collision-resistant hash function, then \(\mathbf{H}\), produced with the Merkle-Damgård transformation, as described above, is also collision-resistant.
You might wonder what “efficiently computable” means in this case, if the input size could be anything. To be precise, we say that the function is efficiently computable if it can be evaluated in time polynomial in \(\ell\) when the input is of length polynomial in \(\ell\).↩︎
You might also see the same concept named the Merkle-Damgård transform, or the Merkle-Damgård construction.↩︎
As before, use some padding if the length of \(\mathbf x\) is not a multiple of \(\ell\).↩︎